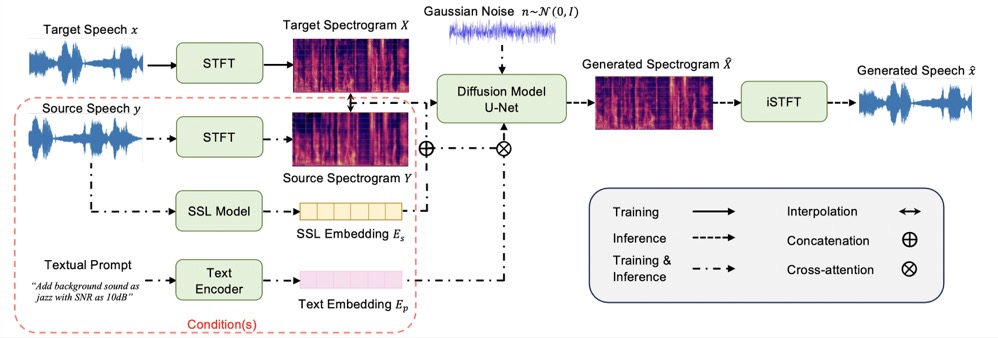
uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models
TL;DR: We build a Unified Speech Enhancement and Editing (uSee) framework with conditional diffusion models to enable fine-grained controllable generation based on both acoustic and textual prompts.